”Life as…” is a blog series where we dive into professionals’ everyday work life and get to learn more about their chosen profession.
Read the section on how it is to work as an Agile Coach.
In this part of ”Life as” we meet Johan Sjögren who works as a Machine Learning Consultant at Neodev.

Johan has been working as a Machine Learning Consultant for the past three years, and before that he worked as a Research Engineer and Accelerator Operator. Johan has a master's degree in physics from Lund University and a PhD in nuclear physics from Glasgow University. Johan is currently working as a Data Scientist as IKEA.
Johan will talk more about what it means to work as a Machine Learning Consultant.
How machine learning and artificial intelligence can create value

We start from the beginning, at the core of everything and dive right into the most important question: “how does machine learning and artificial intelligence create value?”
If a company want to use ML/AI, the purpose is usually to create value for the company. Value can mean different things to different companies. For example, for a profit-driven company value is profit, for an authority it may not be profit in the same way, and a non-profit organization think of value as something else. However, it is still the same question that can be used where the answer is relatively simple: make decisions and better decisions. Making decisions can be connected to automatization, such as data system that makes decisions automatically. Additionally, it could include cloning an expert. If a company wish to expand their business idea, it can sometimes be like a bottle neck; it’s important to have the human expertise available. Although, a data system is a lot easier to copy than a person with 10-20 years’ experience. The other part is to contribute to making better decisions. This is done by taking into consideration the gathered expertise and combining it. It can also involve using complex data. Humans are very good at dealing with some type of complex data such as images and sound to a certain extent. Humans are bad at dealing with another kind of data such as long, difficult tables and statistics since humans don’t have a typical intuition for it. It is then possible to combine making decision and making better decisions to hopefully eventually end up in a better decision.
An example on how to add value can be illustrated with an article that was published in the magazine Forsking & Framsteg from last year. The article is about a machine learning solution where images of moles on the skin were analyzed to classify whether the patients had skin cancer or not. This solution was much better than any doctor. This is an example on how it is possible to create an automatic decision from an image that is better than human decision making. Additionally, it is an example of how to create value by placing better, faster diagnosis on patients; something that probably are appreciated both by the patients and the doctors.
What is machine learning (ML)?
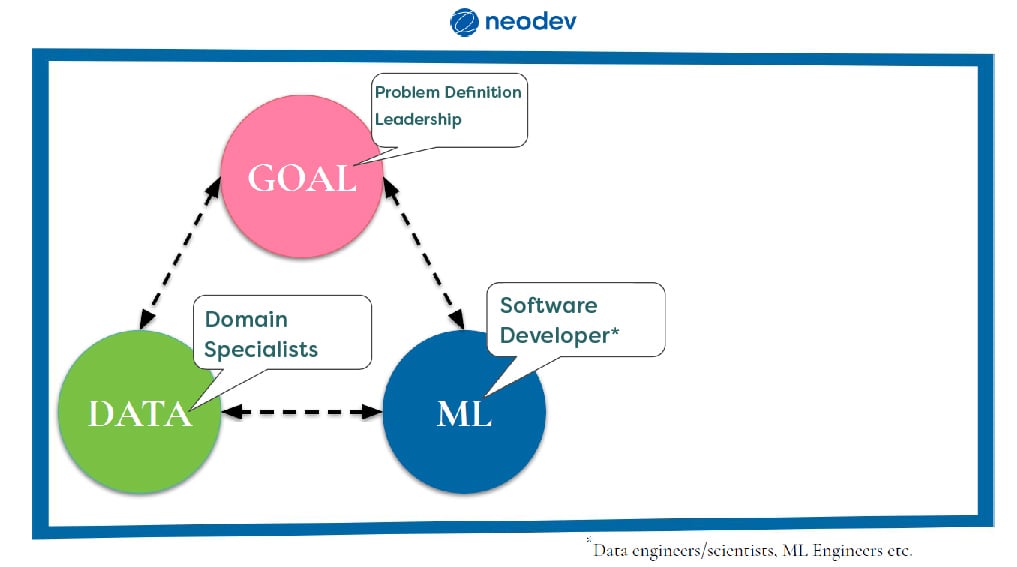
There are some terms, some concepts, that you might have seen before, and it can be difficult for people that do not have the technical background, to see how everything is connected. At this point, it is important to create an understanding of machine learning at an early stage and to make the right prerequisites.
The first thing I usually do is to break down how machine learning fits into an organization, by creating a simple picture, like the triangle above. The triangle is mostly made to make someone’s thoughts and ideas regarding machine learning visible rather than it being a rigid structure. This image is a way to classify problems, possibilities or whatever needs to work on. I have decided to call the different parts in the triangle Goal, Data and ML. The part called Goal is the problem that needs a solution. However, the leadership is also important to define, meaning what we want to accomplish, what vision we have e.tc. The ML-part is primarily characterized by software and developers. At last, we have the data part, which also can be called the expertise part where domain or specialists can be included.
So, what is machine learning? Machine learning can be divided in different categories, and next I will talk about four common variations.
Supervised learning

The first part is called supervised learning. A common example of supervised learning is classification.
To explain classification, I have an example of an image with a lynx. The question to ask is: “what animal can be seen on the picture?” The correct answer is a lynx. To make our model to learn this, we need the image and a correct answer to connect with the picture. In this case, a lynx. This is why it is called supervised learning since there only is one correct answer. There are of course pitfalls when it comes to supervised learning. A question related to this could be:” is it a cat on the picture?” Yes, or it depends on what you mean. It is a cat but not a domesticated cat, it’s a lynx. Here is a challenge with supervised learning. Depending on what target image that are added, meaning what we want to happen, our model will learn from this. The cat is an innocent example, it could of course end with serious consequences if you give your model the completely wrong picture.
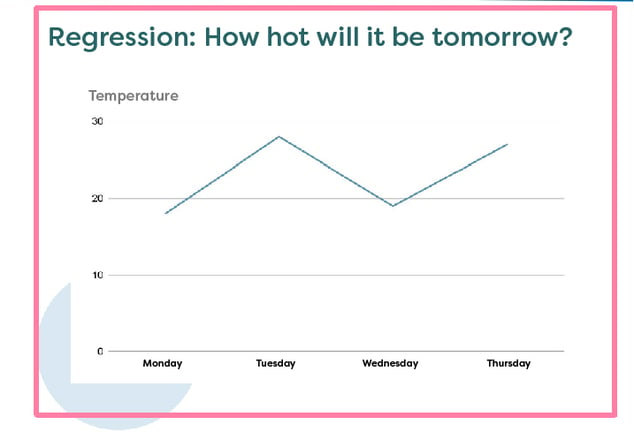
The other example on supervised learning is regression. Regression is used in situations where you want a variable instead of a class, like the example above. A typical example connected to regression, is the weather and the question on how hot it will be tomorrow. This is a difficult regression to work with, something that multiple weather apps have shown.
Unsupervised learning
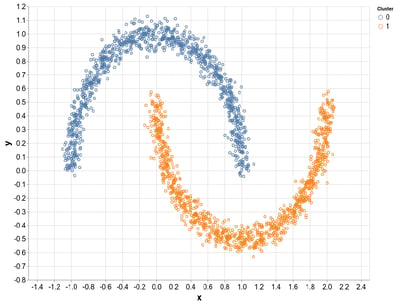
The next part is unsupervised learning. When it comes to unsupervised learning the most important part is the structure in the data and what is being learned. An example of this is that the underlying probability distribution on the data that exist is what will be learned. The major difference between unsupervised learning and supervised learning is that in supervised learning there is one correct answer. This means that if you would for example have 10 000 images, you must go through each picture and tell what the correct answer for every image is. This can of course be time consuming.
In unsupervised learning the structure is the only thing needed to be learnt without ay connection to a correct answer. Unsupervised learning can therefore be seen as a shortcut and can sometimes result in that you stumble upon a structure that correlates with what you are searching for. However, it’s almost only a matter of being lucky. An example of unsupervised learning can be that you want to classify every car brand that appear in a picture. The probability is greater that something that is being classified belong to something else rather than the structure that you search for.
Reinforcement learning
The third part is called reinforcement learning. This part learns by interaction. At first the AI is not very good at it, but after a while, it becomes a lot better. Reinforcement learning is used in a lot of different gaming environments.
Semi-supervised learning
The fourth part is semi-supervised learning. This part learns partially by annotated data (like supervised learning) and partially by the help of structures from unsupervised learning. An example connected to this was when the Panama documents were released in 2016. It was millions of documents that would have been impossible for a journalist to go through. Instead of going through every document, a few documents were marked, about 100 of them. After this, supervised and unsupervised learning was performed on these documents. Then, a new collection of the documents was run through and reviewed how well it had become based on what already had been annotated. If it wasn’t good enough, new documents were used in the training group. This process kept going until they were happy with the accuracy. This way of working created a pretty good filter to take out interesting document without being forced to go through all the millions of documents.
Besides these four parts, search algorithms, planning algorithms and optimization algorithms are included when talking about the AI field besides ML. Something important to keep in mind when it comes to risks with ML, is that the risks don’t disappear because you use AI instead. All problems you face can therefore not be solved just because you change fields.
What does it mean to be a Machine Learning Consultant?
What competencies are needed? You need to know machine learning. And what does that mean? It is partially knowledge in a variation of software libraries, partially knowledge in statistics, mathematical modeling, and other related areas. ML-ops are something that have taken place in recent years. This is because within ML you need other competencies to be able to deliver the solutions to an organization in a reliable matter. It must work integrated in the organization and that sets some other demands than just being able to produce the algorithms. This is what ML-ops means.
AI/ML challenges: implementation and ethics
The connection between goal and ML (see the triangle mentioned before) is often characterized by ignorance. It may not be that strange, since a lot of people think that they don’t know that much about ML. However, it is not that type of ignorance I’m referring to. It is rather the ignorance connected to:” which decision are being made and why are these decisions being made?” and “what are our goals?”. This have not necessarily something to do with ML, instead it is the knowledge about how the organization works, which goals exists and how well different decision works. It is part of the leadership and the vision, to know how good the decisions are and how to measure them, and how much worth there is to make better decisions. At last, this will be translated into something that can be interpretated by a computer or ML-algorithm. Only in that step there is some more knowledge of ML that is needed to be able to answer and find a solution connected to these goals and questions.
Another common challenge when implementing AI/ML, can be called resistance, in some cases good/motivated resistance but in many cases bad resistance. The solution, from the FoF article, that analyze moles, can be seen as a sort of resistance. Why is there no app for this or why is this not being used in health centers etc. For me, knowingly, it does not. We can start with the worse excuses connected to resistance. One excuse could be that the images of the moles were too arranged or that the images were too well-centered and taken in a good lighting. This can collide with the perception that doctors might look at them in a worse lighting and a different angle. This was maybe one of the worst excuses being presented in the article and a clear example of bad resistance.
If we take an example of good resistance, then it is important to think of the goal and if you are satisfied with that goal. A doctor that commits a serious mistake can end up losing their medical license. But what happens if a mistake is made by an AI? This is a question that is relevant in many different areas, where responsibility and ethics play crucial parts. You can ask the question:” is it ethically correct to not use something that is better than what’s being used for now because there is no way to hold someone responsible the same way as a human?” At this point, it is important to think about which goals we want to accomplish, and what’s important. Is the most important that there is the best possible care or is the most important that someone can be held responsible for decisions in health care? Is it possible to do it like this, what happens if we start using AI in this matter, is there any unexpected consequences? This is an important discussion to have and a crucial part within ignorance.
Ignorance can also come from a fear of being replaced by this system in the workplace. Then it is important to go back to the question regarding what kind of goals you have. Is the goal to replace people or to strengthen them? Ultimately, this can of course lead to relatively difficult discussions. What do we do when we don’t need humans for different things anymore, many job opportunities might disappear. On the other hand, the result might leave employees with more time to do other more valuable tasks.
When it comes to other ethical questions regarding AI/ML, it is an area where a lot of work is being done. For example, standards for machine learning are increasingly being created focusing on how data is being used in organizations. Often, I think that when AI/ML is questioned in certain organizations it is mostly the business idea that can be ethically inappropriate and not the AI/ML itself. Another reappearing issue is human versus automation. Take the example of the French airplane that crashed in the Atlantic Ocean, Air France 447, in 2009.
Some reports show that the autopilot was disconnected because of a temporarily error. If they had waited for about 20 seconds and then put on the autopilot again, the airplane wouldn’t have crashed. It crashed because they started doing things the wrong way. We accept people making mistakes, but we are expecting an AI to be perfect. Isn’t it enough that the AI is just better than the human? Perfect is the enemy of the good as you say. Although, it might not be great to be in an AI-driven airplane knowing it is “just better than humans”.
Biggest pitfall in ML/AI
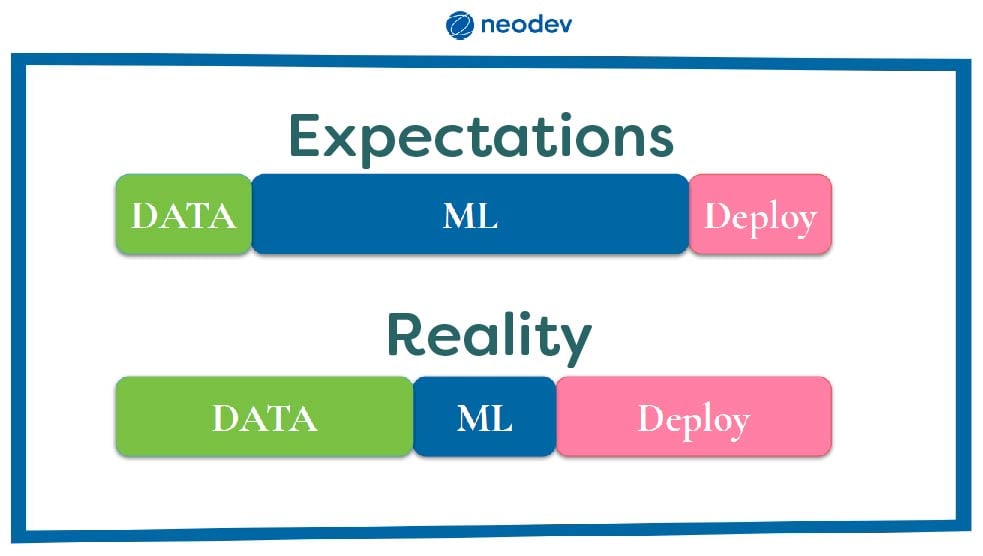
What is really the biggest pitfall regarding ML and AI? This pitfall can appear when you ask the question: “how can we use ML/AI (right now)? People want to use AI/ML as quickly as possible. This is often connected to an unrealistic view of how the situation really is. A lot of people think that the ML-part is the most resource-intensive and time consuming and that the data-part, the actual part of getting the solution to the organization, does not take any time at all. However, it is the ML-part that is a small part and the data-part, the deployment, that takes the most time.

Instead of asking yourself this question: “how can we use ML/AI (right now)?” you should ask yourself: “what do you need to do right now, to be able to use ML/AI later?”. This is connected to what a karate instructor once said to me. To the question:” what is the most important technique?” he answered: “the next technique”. As soon as you are done with the most important part, your next question is what to do next. It took Google several years to replace their search engine with a ML-based algorithm. Google had been around for more than 10 years before they managed to pull it off. That being said, it could take some time to get where you really want to be.
New application areas for AI and ML
I think there are several areas that could benefit a lot from ML, for example the manufacturing industry. For me, knowingly, it’s an area where it’s not being used very much as of today. One application area I see potential in is waste. Waste can be avoided by knowing if a component is defected or not. Of course, there are tests being done at the time of production. However, it can be difficult to connect the whole chain. Two components that will be combined might be produced in different places. It could be a small error in the product, but the product works fine, as long as it is combined with other products that aren’t defected. If a defected component is placed with other defected components, this will result in a product not functioning. In this area, I think it would be great to integrate a ML-model, and at the same time avoid waste since you know which products that can be combined or that you from the beginning don’t sell that product at all.
How do you find a job as a Machine Learning Consultant?
A Society is the consulting company of tomorrow and can help consultants connect with customers who are looking for consultants in the field of machine learning and artificial intelligence. Register an account on the website and you will get a personal contact person who will reach out to you and hear what type of assignment you are looking for. You will also get access to all assignments that are advertised in our network. Joining our network is completely free. Good luck!
